





Phoenix uses OpenTelemetry (OTEL) for seamless setup, full transparency, and no vendor lock-in—start, scale, or move on without restriction.
Easily collect LLM app data with automatic instrumentation — or go manual for utmost control.
Go to Docs

A fast, flexible sandbox for prompt and model iteration. Compare prompts, visualize outputs, and debug failures without leaving your workflow.
Go to Docs
Leverage an eval library with unparalleled speed and ergonomics. Start with pre-built templates, easily customized to any task, or incorporate Human feedback.
Go to Docs
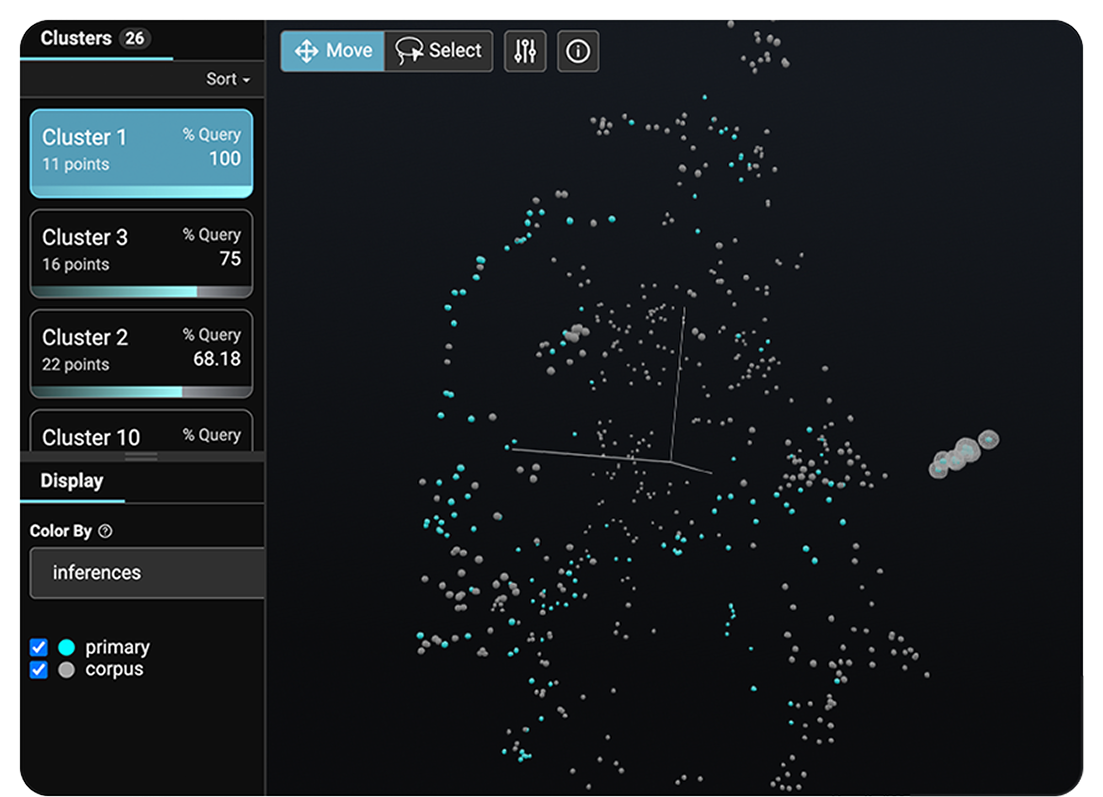
Uncover semantically similar questions, document chunks, and responses using embeddings to isolate poor performance.
Built on top of OpenTelemetry, Phoenix is agnostic of vendor, framework, and language. Phoenix is fully open source and self-hostable — no feature gates or restrictions.

Run model tests, leverage pre-built templates, and seamlessly incorporate human feedback. Customize to fit any project while fine-tuning faster than ever.
































Get the latest news, expertise, and product updates from Phoenix .
